I have a Git question. I kind of know how to do this but in a horrible brut forced way and I’d like to know if there is a “better” or more “elegant” way to do it.
The letters A-I are misleading. The actual repository has around 600 commits (and close to 1000 files/directories).
I have a master branch (A-F) and I created a new branch (G,H,I) and have been actively working on it. The master branch has had a few commits since the branch, but not a lot.

What I’d like to do is create a 2nd repository that only includes E,G,H and I. The old repository is getting huge and the new branch (G,H,I) has become significantly different from the master branch.
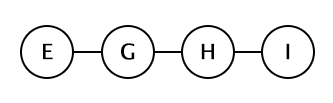
Is there a clean way to do this? I assume it involves –rebase, –reset, –hard, –or-your-fucked flags. I really love Git, it’s amazingly powerful and equally as confusing.
Given there are hundreds of commits and close to a thousand files and directories, I want something that doesn’t involve me having to interact with each commit or rechecking in files. The history from E-I is important to keep (and is way more than 4 commits).